We’re going to look at a very practical starting point with a simple example of getting details from reddit.com.
Let’s start and see how you can do it 😋.

Table of contents
- Getting Started
- Notice about Reddit
- New version of Reddit
- Old version of Reddit
- Getting technical 👨💻
- Tools Choice
- Iterating and getting all the posts
- Full Code
- Learning more 📚
Getting Started
Firstly, if you are just starting out and scraping is something new to you, I would suggest to go and check out some of the other blog posts:
Alright, so if you’re still here, let’s get started 💻.
Notice about Reddit
Since there are actually 2 versions of the same reddit website, I am going to choose one over the other for scraping purposes.
New version of Reddit
The new version of ready is currently the main one which is live on their website, which people actually use.
It is more modern and it is more javascript based with content that is loading dynamically.
Old version of Reddit
Some of you may know and some may not, the older version can still be accessed through the following url:
The old reddit gives us a much better option when scraping because the content is provided directly and they do not use dynamic content loading as much as in the new version.
Because we can get more html and content with a simple NodeJs request, we are going to use the older version, which has the same content, over the newer one.
Note
I would not recommend trying to scrape the New version without a solution like Puppeteer or Nightmare simply because it doesn’t make sense to create all the needed requests manually in order to get the content.
Getting technical 👨💻
The first thing that you always gotta’ do when starting a web scraping project is to investigate and get familiar with the website you want to scrape.
This will help you understand what you need to do and will give you a deeper technical advantage.
I chose a simple subreddit and accessed it, right clicked on the actual discussion and inspected the element via Chrome.
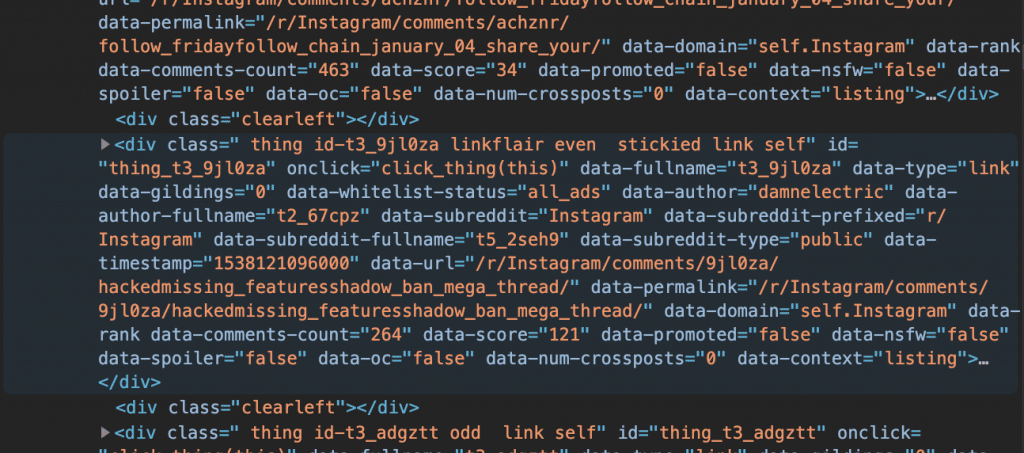
By investigating we right of the bat understand that we have the main are which holds the content under the #siteTable id and inside of it, all the discussions can be easily accessed under the div’s that have the class of .thing and the other classes don’t even matter now.
You can easily test the results directly in the Chrome Console by using javascript’s query selector, just like this
document.querySelectorAll('#siteTable > .thing');
Ps: The full code is ready at the end, so stay tuned for that
Tools Choice
For this example and since it is more of a beginner’s choice, here is what we are using:
- Request + Request-Promise
- Cheerio
That’s all you need for a basic scraper.
Since, as mentioned above, we are using the old version of Reddit, we can simply use a direct request to reddit and get all the html needed and use Cheerio to parse through it and get what we need.
Iterating and getting all the posts
Once we have all the posts, while we get them, we must take other details from them also.
Here’s what we’re gonna get for this example:
- Score
- Time ( Posted time )
- Author Name
- Comments
- Title
And if you want to get more details, you are free to extend this code and let me know, I’m gonna share it here on in another blog post and mention you 👋.

As you can see from the above picture, the class names are pretty straight forward and not complicated at all to use in order to get what you want.
Full Code
Here’s the code ready to be copy pasted and used:
const request = require('request-promise');
const cheerio = require('cheerio');
const start = async () => {
const SUBREDIT = 'Instagram';
const BASE_URL = `https://old.reddit.com/r/${SUBREDIT}/`;
let response = await request(
BASE_URL,
{
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'en-US,en;q=0.9,fr;q=0.8,ro;q=0.7,ru;q=0.6,la;q=0.5,pt;q=0.4,de;q=0.3',
'cache-control': 'max-age=0',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
);
let $ = cheerio.load(response);
let posts = [];
$('#siteTable > .thing').each((i, elm) => {
let score = {
upvotes: $(elm).find('.score.unvoted').text().trim(),
likes: $(elm).find('.score.likes').text().trim(),
dislikes: $(elm).find('.score.dislikes').text().trim(),
}
let title = $(elm).find('.title').text().trim();
let comments = $(elm).find('.comments').text().trim();
let time = $(elm).find('.tagline > time').attr('title').trim();
let author = $(elm).find('.tagline > .author').text().trim();
posts.push({
title,
comments,
score,
time,
author
});
})
console.log(posts);
}
start();
Learning more 📚
Also if you want to learn more and go much more in-depth with the downloading of files, I have a great course with hours of good content on web scraping with nodejs.
Your approach is really different in comparison to other bloggers I have checked articles from.
Thank you so much for posting when you have got the time, reckon I will just bookmark this one.