I was curious to see how hard it would be to scrape the dev.to website and I did that.
Here are the results about it..

Table of contents
- The Plan 💻
- Difficulty
- How did I scrape it? 🤔
- 1. From a beginners perspective
- 2. From my perspective
- Full code 🤑
- Learning more 📚
The Plan 💻
I’m going to make this short and simple without too much talking and keep in mind, the full code will be available below 🔥
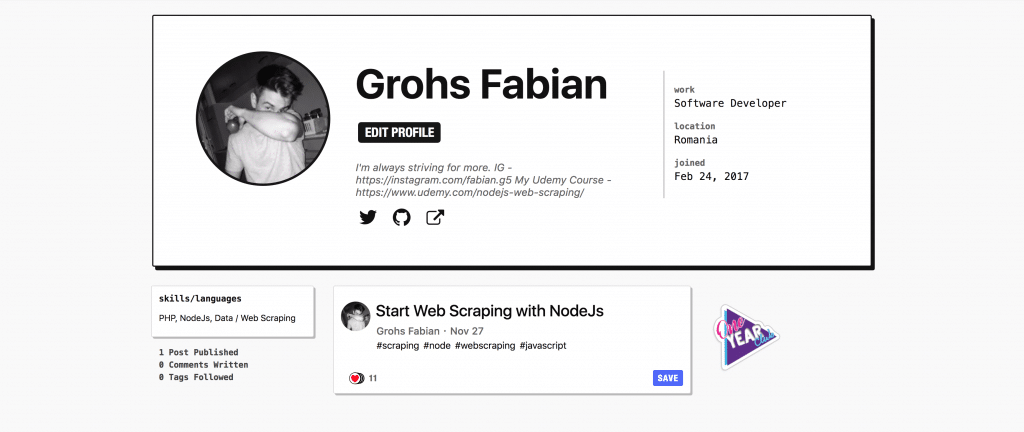
The dev.to website is a community for developers where each one can write about anything related to programming and tech.
Since everybody has a profile link for their accounts..
I want to access that link and parse everything that I want, pretty straight forward.
Example link would be my profile, which is dev.to/grohsfabian.
Difficulty
The first thing that you gotta do before you start building a scraper is to investigate.
By investigate I mean look around the website, see how it works and also check the source.
Checking the source and looking around will determine the difficulty and let you know how that website functions and what you need to do in order to scrape it.
After 2-5 minutes of looking around I discovered that the classes are not dynamic, the format of the html is not weird, the website doesn’t render after the initial load and on top of that, the structure and the classes of the html are on point.
This results in a very easy scraping and without much effort. From my perspective, this page that I wanted to scrape was way more than easy.
How did I scrape it? 🤔
Let’s look into how I created the scraper for dev.to with NodeJs and just 2 other libraries that I also discussed in other of my articles ( 4 Easy Steps to Get Started with NodeJs Scraping ).
1. From a beginners perspective
Since I was scraping the dev.to website with NodeJs, I figured I can write an article on their side about this also so that people get to see how I did it.
Here is the link to that article: Web Scraping with NodeJs
2. From my perspective
And since so many of you seem to like these scraping videos from my youtube channel ( Fabian Grohs ) I figured I would show you my thinking on how I went about doing this.
So, here it is, the video of me building a scraper from start to finish on NodeJs with nothing else but Cheerio and Request-Promise
Full code 🤑
Either if you are here just to investigate the code or you genuinely read the article / watched the video, I’m glad that you did.
Please take a note that you should NOT use this code for malicious intent or spam.
const request = require('request-promise')
const cheerio = require('cheerio');
const BASE_URL = 'https://dev.to/';
const USERNAME = 'grohsfabian';
(async () => {
let response = await request(`${BASE_URL}${USERNAME}`);
let $ = cheerio.load(response, { normalizeWhitespace: true });
/* parse details from page */
let fullName = $('span[itemprop="name"]').text().trim();
let description = $('p[itemprop="description"]').text().trim();
let profilePictureUrl = $('div[class="profile-pic-wrapper"] > img').attr('src');
/* Parsing socials */
let socials = [];
$('p[class="social"] > a').each((index, elm) => {
let url = $(elm).attr('href');
socials.push(url);
})
/* Parsing the details */
let details = {};
$('div[class="user-metadata-details-inner"] > div[class="row"]').each((index, elm) => {
let key = $(elm).find('.key').text().trim();
let value = $(elm).find('.value').text().trim();
details[key] = value;
})
/* Parse statistics */
let statistics = [];
$('div[class="sidebar-data"] > div').each((index, elm) => {
let string = $(elm).text().trim();
statistics.push(string);
})
/* Parsing some extra data */
let widgets = {};
$('div[class="user-sidebar"] > div[class="widget"]').each((index, elm) => {
let key = $(elm).find('header').text().trim();
let value = $(elm).find('.widget-body').text().trim();
widgets[key] = value;
})
console.log({
widgets,
statistics,
details,
fullName,
description,
profilePictureUrl,
socials
})
})();
Learning more 📚
Also if you want to learn more and go much more in-depth with the downloading of files, I have a great course with more hours of secret content on web scraping with nodejs.